
¿Qué es Robots.txt y qué puedes hacer con él? )

¿Qué es un archivo robots.txt?
Robots.txt es un archivo de texto breve que indica a los rastreadores web (por ejemplo, Googlebot) lo que pueden rastrear en su sitio web.
Desde una perspectiva de SEO, robots.txt ayuda a rastrear primero las páginas más importantes y evita que los bots visiten páginas que no son importantes.
Así es como se vería robots.txt:

Dónde encontrar robots.txt
Encontrar archivos robots.txt es bastante fácil: vaya a la página de inicio de cada dominio y agregue "/robots.txt" al final.
Le mostrará un archivo robots.txt real y en funcionamiento, aquí hay un ejemplo:
https://yourdomain.com/robots.txt
El archivo Robots.txt es una carpeta pública que se puede consultar en prácticamente cualquier sitio web; incluso se puede encontrar en sitios como Amazon, Facebook o Apple.
¿Por qué es importante robots.txt?
El propósito del archivo robots.txt es decirle a los robots a qué partes de su sitio web tienen acceso y cómo deben interactuar con las páginas.
En términos generales, es importante que el contenido del sitio web se pueda rastrear e indexar primero: los motores de búsqueda necesitan encontrar sus páginas antes de que puedan aparecer como resultados de búsqueda.
Sin embargo, en algunos casos es mejor evitar que los rastreadores web visiten ciertas páginas (por ejemplo, páginas en blanco, página de inicio de sesión de su sitio web, etc.).
Esto se puede lograr mediante el uso de un archivo robots.txt, que los robots siempre verifican antes de comenzar a rastrear el sitio web.
Nota: El archivo Robots.txt puede evitar que los motores de búsqueda rastreen, pero no indexen.
Aunque es posible que los robots no puedan visitar una página en particular, los motores de búsqueda aún pueden indexarlo si algunos enlaces externos apuntan a él.
Por lo tanto, esta página indexada puede aparecer como un resultado de búsqueda, pero sin ningún contenido útil, ya que los robots no pueden rastrear ningún dato en la página:

Para evitar que Google indexe sus páginas, use otros métodos apropiados (como la metaetiqueta noindex) para indicar que no desea que ciertas partes de su sitio web aparezcan como resultados de búsqueda.
Además del propósito principal del archivo robots.txt, existen algunos beneficios de SEO que pueden ser útiles en ciertas situaciones.
1. Optimiza tu presupuesto de rastreo
El presupuesto de rastreo determina la cantidad de páginas que los rastreadores web, como Googlebot, rastrearán (o rastrearán) durante un período de tiempo.
Los sitios web mucho más grandes generalmente contienen toneladas de páginas sin importancia que no necesitan ser rastreadas e indexadas con frecuencia (o en absoluto).
El uso de robots.txt le dice a los motores de búsqueda qué páginas rastrear y cuáles evitar por completo - que optimiza la eficiencia y la frecuencia de la fluencia.
2. Gestión de contenido duplicado
Robots.txt puede ayudarlo a evitar rastrear contenido similar o duplicado en sus páginas.
Muchos sitios web contienen algún tipo de contenido duplicado, ya sea que haya páginas con parámetros de URL, www o www. páginas que no son www, archivos PDF idénticos, etc.
Al especificar estas páginas a través de robots.txt, puede administrar contenido que no necesita ser rastreado y ayudar al motor de búsqueda a rastrear solo aquellas páginas que desea que aparezcan en la Búsqueda de Google.
3. Evite la sobrecarga del servidor
El uso de robots.txt puede ayudar a evitar que el servidor de un sitio web se bloquee.
En términos generales, Googlebot (y otros robots de buena reputación) suelen ser buenos para determinar qué tan rápido deben rastrear su sitio web sin sobrecargar la capacidad de su servidor.
Sin embargo, es posible que desee bloquear el acceso a los robots que visitan su sitio con demasiada frecuencia.
En estos casos, robots.txt puede decirles a los robots en qué páginas específicas enfocarse, dejando en paz otras partes del sitio web y evitando así la congestión del sitio.
o como Martín SplitEl abogado desarrollador de Google explicó:
"Esta es la tasa de rastreo, esencialmente la cantidad de estrés que podemos poner en su servidor sin bloquear algo o sufrir por matar demasiado su servidor."
Además, es posible que desee bloquear ciertos bots que causan problemas con su sitio, ya sea un bot "malo" que abruma su sitio con consultas o bloquea a los patinadores que intentan copiar todo el contenido de su sitio web.
¿Cómo funciona el archivo robots.txt?
Los principios básicos de cómo funciona un archivo robots.txt son bastante simples: consta de 2 elementos básicos que dictan qué robot web debe hacer algo y qué debe ser exactamente:
- Agentes de usuario: indicar qué robots serán el objetivo para evitar (o rastrear) ciertas páginas
- Directivas: le dice a los agentes de usuario qué hacer con ciertas páginas.
Este es el ejemplo más simple de cómo se vería un archivo robots.txt con estos 2 elementos:
User-agent: Googlebot Disallow: /wp-admin/
vamos echemos un vistazo más de cerca a ambos.
agentes de consumo
User-agent es el nombre de un robot específico que será instruido por directivas sobre cómo rastrear su sitio web.
Por ejemplo, el agente de usuario de Google Shared Robot es "Robot de Google"El trabajo de Bing es"BingBot"Acerca de Yahoo"Estrujar", Etc.
Para seleccionar todos los tipos de rastreadores web para una directiva en particular a la vez, puede usar el " * "(Llamado comodín) - representa todos los bots que "obedecen" al archivo robots.txt.
El archivo robots.txt se verá así:
User-agent: * Disallow: /wp-admin/
Nota: Tenga en cuenta que existen muchos tipos de agentes de usuario, cada uno de los cuales se centra en el rastreo para diferentes propósitos.
Si quieres ver qué agentes de usuario usa Google, echa un vistazo a esto Revisión de robots de Google.
directivas
Las directivas de Robots.txt son las reglas que seguirá el agente de usuario especificado.
De forma predeterminada, se indica a los rastreadores que rastreen todas las páginas web disponibles: robots.txt luego especifica qué páginas o secciones de su sitio web no se deben rastrear.
Hay 3 reglas más comunes que se utilizan:
- "Prohibir" - le dice a los robots que no accedan a nada especificado en esta directiva. Puede establecer varias instrucciones para deshabilitar los agentes de usuario.
- "permite" - le dice a los robots que tienen acceso a algunas páginas de la sección ya prohibida del sitio.
- "Mapa del sitio" - Si ha configurado un mapa del sitio XML, robots.txt puede apuntar a los rastreadores web donde pueden encontrar las páginas que desea rastrear al señalarlas a su mapa del sitio.
Aquí hay un ejemplo de cómo se vería robots.txt con estas 3 directivas simples:
User-agent: Googlebot Disallow: /wp-admin/ Allow: /wp-admin/random-content.php Sitemap: https://www.example.com/sitemap.xml
En la primera línea, encontramos que la directiva se aplica a un robot específico: Googlebot.
En la segunda línea (directiva) le dijimos a Googlebot que no queremos que tenga acceso a una carpeta específica, en este caso, la página de inicio de sesión de un sitio de WordPress.
Agregamos una excepción en la tercera fila, aunque Googlebot no tiene acceso a nada a continuación. /wp-admin/ carpeta, puede visitar una dirección específica.
Con la cuarta línea, le indicamos a Googlebot dónde encontrarlo. Sitemap con una lista de URL que desea rastrear.
Hay algunas otras reglas útiles que se pueden aplicar a su archivo robots.txt, especialmente si su sitio contiene miles de páginas que deben administrarse.
* (comodín)
el comodín * es una directiva que especifica una regla para patrones coincidentes.
La regla es especialmente útil para sitios web que contienen toneladas de contenido generado, páginas de productos filtradas, etc.
Por ejemplo, en lugar de prohibir cualquier página de producto en /products/ sección por separado (como en el siguiente ejemplo):
User-agent: * Disallow: /products/shoes? Disallow: /products/boots? Disallow: /products/sneakers?
Podemos usar el comodín para deshabilitarlos todos a la vez:
User-agent: * Disallow: /products/*?
En el ejemplo anterior, se le indica al agente de usuario que no rastree ninguna página a continuación /products/ sección que contiene el signo de interrogación "?" (a menudo se usa para URL de categorías de productos parametrizados).
ps
EN $ el símbolo se utiliza para indicar el final de una URL: se puede indicar a los robots que no rastreen (o no deberían) rastrear las URL con un final específico:
User-agent: * Disallow: /*.gif$
" $ "El letrero le dice a los bots que ignoren todas las URL que terminan en".gif".
#
EN # el signo sirve solo como comentario o anotación para lectores humanos; no tiene influencia en ningún agente de usuario, ni sirve como directiva:
# We don't want any crawler to visit our login page! User-agent: * Disallow: /wp-admin/
Cómo crear un archivo robots.txt
Crear su propio archivo robots.txt no es ciencia espacial.
Si usa WordPress para su sitio, ya tendrá un archivo robots.txt básico creado, similar a los que se muestran arriba.
Sin embargo, si planea realizar algunos cambios adicionales en el futuro, existen algunos complementos simples que pueden ayudarlo a administrar su archivo robots.txt, como:
Estos complementos facilitan el control de lo que desea permitir y deshabilitar sin tener que escribir ninguna sintaxis compleja usted mismo.
Alternativamente, también puede editar su archivo robots.txt a través de FTP; si confía en acceder y editarlo, entonces cargar un archivo de texto es bastante fácil.
Sin embargo, este método es mucho más complicado y puede conducir rápidamente a errores.
Cómo comprobar el archivo robots.txt
Hay muchas maneras de verificar (o probar) su archivo robots.txt: primero, debe intentar encontrar robots.txt usted mismo.
A menos que haya especificado una URL específica, su archivo se alojará en "https://tudominio.com/robots.txt"- si usa un creador de sitios web diferente, la URL específica puede ser diferente.
Para ver si los motores de búsqueda como Google realmente pueden encontrar y "obedecer" su archivo robots.txt, puede:
- Utilice un probador de robots.txt - Una sencilla herramienta de Google que puede ayudarte a averiguar si tu archivo robots.txt funciona correctamente.
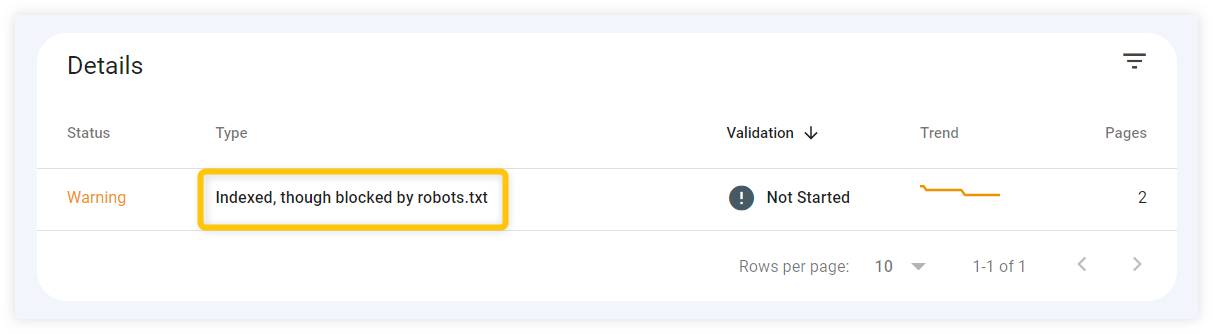
- Echa un vistazo a la consola de búsqueda de Google - Puedes buscar cualquier errores causados por robots.txt en "Cobertura"Sección Consola de búsqueda de Google. Asegúrate de que no haya URL que comuniquen mensajes".bloqueado por robots.txt"Involuntariamente.
Mejores prácticas para Robots.txt
Los archivos Robots.txt pueden volverse complejos fácilmente, por lo que es mejor mantener las cosas lo más simples posible.
Estos son algunos consejos que le ayudarán a crear y actualizar su propio archivo robots.txt:
- Use archivos separados para subdominios - Si su sitio web tiene varios subdominios, debe tratarlos como sitios web separados. Cree siempre archivos robots.txt separados para cada subdominio que posea.
- Especifique los agentes de usuario solo una vez - Intente combinar todas las directivas que se asignan a un agente de usuario específico. Esto creará simplicidad y organización en su archivo robots.txt.
- Proporcionar especificidad - Asegúrese de especificar las rutas URL exactas y preste atención a las barras o caracteres específicos que están presentes (o que faltan) en sus URL.
Deja una respuesta