
Seguimiento de las actualizaciones y la volatilidad del algoritmo del gráfico de conocimiento de Google

Al igual que el algoritmo central, el Gráfico de conocimiento de Google se actualiza periódicamente.
Pero se ha sabido poco sobre cómo, cuándo y qué significa, hasta ahora.
Creo que estas actualizaciones constan de tres cosas:
- Ajustes de algoritmo.
- Una inyección de datos de entrenamiento seleccionados.
- Una actualización del conjunto de datos de Knowledge Graph.
Mi empresa, Kalicube, ha estado rastreando el Gráfico de conocimiento de Google tanto a través de la API como a través de paneles de conocimiento durante varios años.
Cuando escribí sobre The Budapest Update 'en 2019, por ejemplo, había visto un aumento masivo en los puntajes de confianza. Desde entonces no ha sucedido nada tan sísmico en las puntuaciones.
Sin embargo, las puntuaciones de las entidades individuales fluctúan mucho y, por lo general, más del 75% cambiarán durante un mes determinado.
Las excepciones son diciembre de 2019 y durante los últimos cuatro meses (hablaré de eso más adelante).
Desde julio de 2019 hasta junio de 2020, realizamos un seguimiento mensual (de ahí las cifras mensuales).
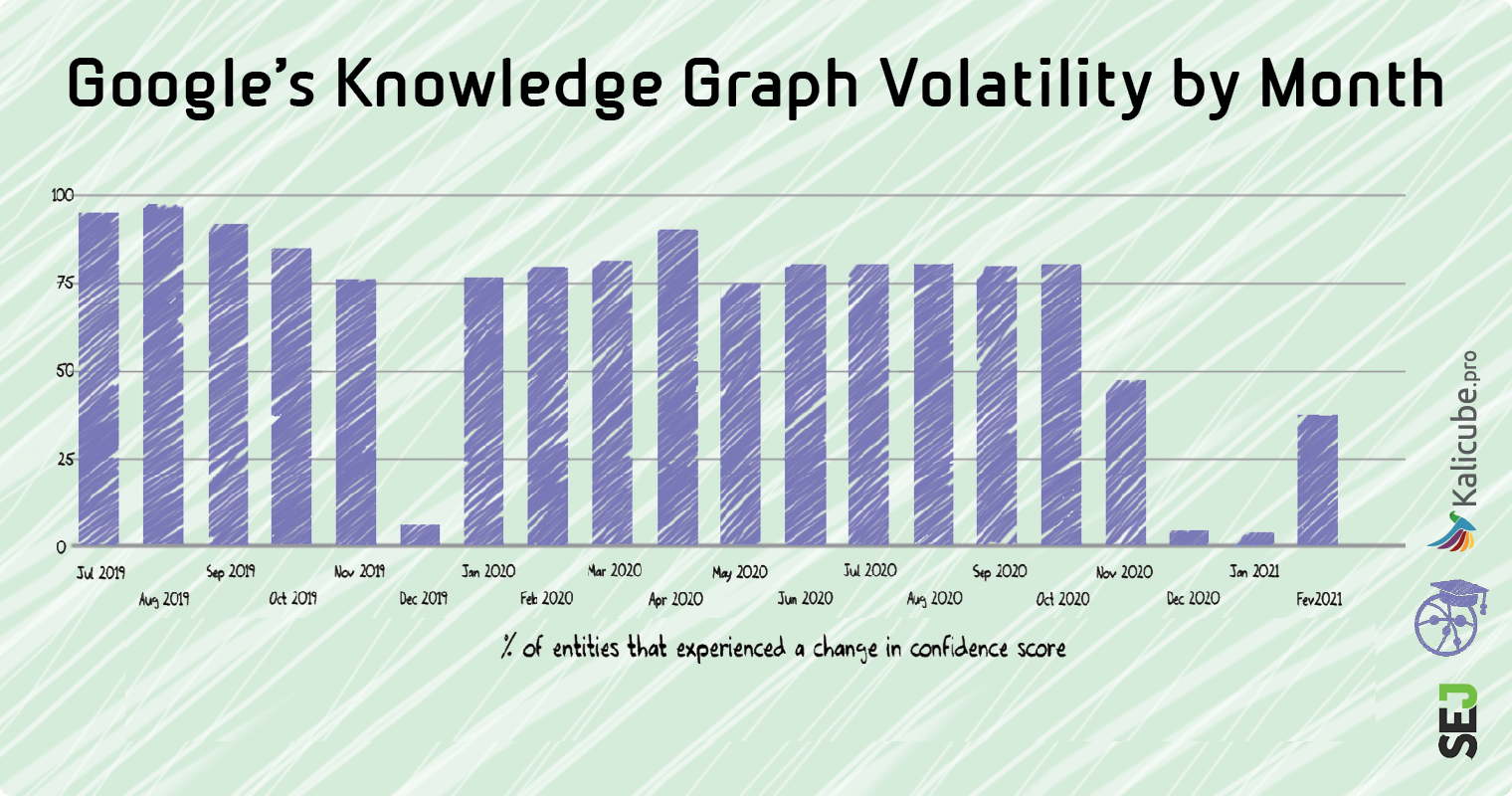
Desde julio de 2020, hemos realizado un seguimiento diario para ver si podemos detectar patrones más granulares. No había visto ninguno hasta que una conversación con Andrea Volpini de Wordlift me envió por un agujero de conejo ...
Y allí descubrí algunas ideas realmente asombrosas.
Nota: Este artículo trata específicamente sobre los resultados devueltos por la API y la información que nos brindan cuando Google actualiza su Gráfico de conocimiento, incluido el tamaño, la naturaleza y el día de la actualización, que es un cambio de juego si me preguntas.
Principales actualizaciones de Knowledge Graph durante los últimos 8 meses
- Domingo 12 de julio de 2020.
- Lunes 13 de julio de 2020.
- Miércoles 12 de agosto de 2020.
- Sábado 22 de agosto de 2020.
- Miércoles 9 de septiembre de 2020.
- Sábado 19 de septiembre de 2020.
- Domingo 11 de octubre de 2020.
- Jueves 11 de febrero de 2021.
- Jueves 25 de febrero de 2021.

Puede consultar las actualizaciones del sensor de gráficos de conocimiento de Kalicube aquí (actualizado diariamente).
Para cualquiera que siga las actualizaciones del algoritmo de enlace azul central, puede notar que los dos no están sincronizados, hasta las actualizaciones de febrero de 2021.
Las excepciones que encontré son (con mi salvaje teorización en cursiva):
- los 11 de octubre actualización que está incómodamente cerca del error de indexación del 12 de octubre de 2020, informado por Moz.
¿Podría ser que la pausa de 3 meses en las actualizaciones de Knowledge Graph se deba simplemente a que, durante esos meses, Google fusionó los dos conjuntos de datos y que Knowledge Graph tomó una pausa de 3 meses mientras trabajaban en los problemas de ese movimiento masivo? - los 11 de febrero actualización que ocurrió solo un día después del cambio a Passage Indexing (10 de febrero de 2021).
¿Podría la indexación basada en pasajes significar una indexación basada en entidades? La indexación basada en pasajes consiste en dividir las páginas para extraer mejor las entidades. - los 25 de Febrero La actualización coincide con la volatilidad en los SERP de Google ampliamente informada el 25 y 26 de febrero de 2021.
¿Podría ser esto una señal de que el algoritmo central y el gráfico de conocimiento ahora están sincronizados y los resultados basados en entidades son ahora una realidad?
Alcance, alcance y escala de estas actualizaciones
Podemos considerar útilmente tres aspectos de una actualización:
- los magnitud (alcance / amplitud), que es el porcentaje de entidades afectadas (hasta ahora, entre el 60-80%).
- los amplitud (alcance / altura), o el cambio (hacia arriba o hacia abajo) en los puntajes de confianza en un micro, por nivel de entidad (la amplitud promedio para los cincuenta medios ha sido de alrededor del 10-15%).
- los cambio (escala / profundidad), que es el cambio en las puntuaciones de confianza a nivel macro (aparte de la actualización de Budapest, esto es menos del 0,1%).
Lo que encontramos al rastrear el gráfico de conocimiento diariamente
El Gráfico de conocimiento tiene actualizaciones muy regulares.
Estas actualizaciones ocurren cada 2 o 3 semanas, pero a veces con largas pausas, como puede ver arriba.
Las actualizaciones son violentas y repentinas.
Vemos que el 60-80% de las entidades se ven afectadas y los cambios probablemente sean inmediatos en todo el conjunto de datos.
Las actualizaciones de entidades individuales continúan en el medio.
Cualquier entidad individual puede ver su puntaje de confianza aumentar o disminuir cualquier día, ya sea que haya una actualización o no. Puede desaparecer (en una bocanada de humo virtual) y la información sobre esa entidad puede cambiar en cualquier momento entre estas actualizaciones importantes del algoritmo y los datos del Gráfico de conocimiento.
Hay casos extremos extremos.
Las entidades individuales reaccionan de manera muy diferente. En cada actualización (e incluso en el medio), algunos cambios son extremos. Una puntuación de confianza puede multiplicarse por varias en un día. Puede caer varias veces. Y una entidad puede desaparecer por completo (cuando reaparece, tiene una nueva identificación).
Hay un techo.
La puntuación de confianza promedio para todo el conjunto de datos rara vez cambia en más de una décima parte del uno por ciento por día (el turno), incluso en los días en los que se produce una actualización importante.
Parece que puede haber un límite máximo a las puntuaciones que el sistema puede atribuir, presumiblemente para evitar que las entidades más dominantes desplacen por completo al resto (gracias a Jono Alderson por esa sugerencia).
Tras el aumento masivo de ese límite máximo durante la actualización de Budapest, el límite máximo parece no haberse movido de manera significativa desde entonces.
Cada actualización desde Budapest afecta tanto al alcance como al alcance. Ninguno desde Budapest ha provocado un cambio importante en la escala.
Es posible que el techo nunca vuelva a cambiar. Pero entonces puede ser. Y si lo hace, será grande. Así que estad atentos (e idealmente, prepárate).
Después de mucha experimentación, hemos aislado y excluido esos valores atípicos extremos.
Los rastreamos y continuamos tratando de ver cualquier patrón obvio. Pero esa es una historia para otro día.
Cómo estamos midiendo
Hemos aislado cada uno de los tres aspectos de los cambios y los medimos diariamente en un conjunto de datos de 3000 entidades. Medimos:
- Cuántas entidades vieron un aumento o una disminución (alcance / amplitud / magnitud).
- Qué tan significativo fue ese cambio a nivel micro (alcance / altura / amplitud).
- Qué tan significativo fue el cambio en la puntuación general (escala / profundidad / cambio).
¿Qué está pasando?
Una cosa está clara: estas actualizaciones han sido violentas, de gran alcance y repentinas.
Alguien en Google tenía (y tal vez todavía tenga) "un gran botón rojo".
Bill Slawski me mencionó una patente de Bing que menciona exactamente ese proceso.
Las dos últimas actualizaciones de los jueves suenan al mantra de los desarrolladores "nunca cambies nada los viernes si no quieres trabajar el fin de semana".
Un baile de gráficos de conocimiento de Google
Slawski me sugirió un concepto que creo que dice mucho. Google ha estado jugando "sillas musicales" con los datos: los algoritmos centrales y el algoritmo del Gráfico de conocimiento tienen necesidades muy diferentes.
- Los algoritmos centrales se basan fundamentalmente en la popularidad. (la probabilidad de que los enlaces entrantes conduzcan a su sitio), mientras que el Gráfico de conocimiento necesariamente debe dejar de lado esa popularidad / probabilidad y considerar la confiabilidad / veracidad probable / autoridad; en otras palabras, la confianza.
- Los algoritmos centrales se centran en cadenas de caracteres / palabras., mientras que el Gráfico de conocimiento se basa en la comprensión de las entidades que representan esas mismas palabras.
Es posible que las actualizaciones del núcleo y los algoritmos del Gráfico de conocimiento estuvieran necesariamente desincronizadas, ya que Google tenía que "reorganizar" los datos para cada enfoque cada vez que querían actualizar cualquiera de los dos y luego volver a cambiar.
¿Recuerdas el Google Dance en su día?
En ese momento, era simplemente una carga por lotes de datos de enlaces nuevos. Esto podría haber sido algo similar.
A partir de febrero de 2021, ¿ha terminado el baile?
Queda por ver si eso es ahora un "problema resuelto".
Me imagino que veremos algunos bailes más desincronizados y algunos errores más extraños debido a las actualizaciones de cada uno que se contradicen entre sí.
Pero que para fines de 2021, los dos se fusionarán a todos los efectos y la búsqueda basada en entidades será una realidad que nosotros, como especialistas en marketing, podemos aprovechar de manera productiva y mensurable.
Independientemente de cómo evolucionen y progresen los algoritmos, el cambio subyacente es sísmico.
Clasificar el corpus de datos que posee Google en entidades y organizar esa información de acuerdo con la confianza en su comprensión de esas entidades es una enorme pasar de organizar esos mismos datos por pura relevancia (como ha sido el caso hasta ahora).
¿La convergencia de los algoritmos?
Opinión: Las siguientes cosas me hacen pensar que el invierno 2020/2021 fue el momento en que Google realmente implementó el cambio "de la cadena a las cosas" (después de cinco años de relaciones públicas):
- La pausa de tres meses de octubre a febrero, cuando el algoritmo central estaba relativamente activo, pero las actualizaciones del Gráfico de conocimiento estaban claramente en pausa.
- El anuncio de que la capa temática estaba activa en noviembre.
- La introducción de la indexación basada en pasajes en el algoritmo central en febrero que parece centrarse en la extracción de entidades.
- La aparente convergencia de las actualizaciones (esto es nuevo; solo tenemos dos actualizaciones para juzgar, y nuestro seguimiento podría demostrar que estoy equivocado en esta, por supuesto).
El gráfico de conocimiento es algo vivo
El Gráfico de conocimiento parece estar basado en un enfoque de lago de datos en lugar del enfoque de río de datos del algoritmo central actual (reacción retardada versus efecto inmediato).
Sin embargo, el hecho de que las entidades cambien y se muevan entre estas actualizaciones importantes y el hecho de que las actualizaciones parecen estar convergiendo sugiere que no estamos lejos de un algoritmo de Gráfico de conocimiento que no solo funciona en ríos de datos nuevos, sino que también está integrado como parte y paquete del algoritmo central.
Aquí hay un ejemplo específico que asigna las actualizaciones a los cambios en la puntuación de confianza de mi nombre (uno de mis experimentos).
Esa vertiginosa caída no se corresponde con una actualización.
Fue un error de mi parte y muestra que las actualizaciones de entidades individuales están en curso, ¡y pueden ser extremas!
Lea sobre ese desastre en particular aquí en mi contribución a un artículo de SE Ranking.

El futuro
Mi opinión: El "gran botón rojo" se retirará progresivamente y las actualizaciones violentas y repentinas serán reemplazadas por cambios y turnos que son más suaves y menos visibles.
La integración de entidades en los algoritmos de enlaces azules centrales será cada vez más incremental e imposible de rastrear (así que aprovechemos al máximo mientras podamos).
Está claro que Google se está moviendo rápidamente hacia una comprensión casi humana del mundo y todos sus algoritmos dependerán cada vez más de su comprensión de las entidades y de su confianza en su comprensión.
El mundo del SEO tendrá que acoger realmente a las entidades y centrarse cada vez más en educar a Google a través de su Gráfico de conocimiento.
Conclusión
En este artículo me he ceñido a propósito a cosas de las que estoy bastante seguro de que serán ciertas.
Tengo cientos de ideas, teorías y planes, y mi empresa sigue rastreando más de 70.000 entidades mensualmente, más de 3.000 al día.
También estoy ejecutando más de 500 experimentos activos en el Gráfico de conocimiento y los paneles de conocimiento (incluido yo mismo, el perro azul y el koala amarillo), así que espero más noticias pronto.
Mientras tanto, ¡solo espero que Google no me corte el acceso a la API de Knowledge Graph!
Deja una respuesta