
Google+ KELM: una forma de achicar la distorsión y mejorar la precisión real

Recientemente, Google plus AI anunció que KELM es una manera de reducir el contenido engañoso y malicioso en los resultados de búsqueda. Además de esto, aquí se explica de qué manera puede progresar el método de precisión real llamado TEKGEN, que transforma los datos del gráfico de conocimiento en artículo en lenguaje natural que entonces se puede usar para mejorar el modelo de procesamiento.
- ¿Qué es Kelm?
- KELM utiliza datos enormemente confiables
- ¿Google plus utiliza KELM?
- Distorsión, precisión real y resultados de la búsqueda
- KELM puede llevar a cabo más que influir en los resultados de la búsqueda
- KELM asimismo está de forma indirecta con MUM. relacionados
- El aprendizaje automático puede producir desenlaces ilusorios
- Gráfico de conocimiento Gráfico de conocimiento
- Mapa capaz y precisión práctica
- Desde datos estructurados en gráficos de conocimiento hasta texto en lenguaje natural
- El artículo en lenguaje natural de TEKGEN optimización la precisión de los hechos
- Crea un cuerpo KELM
- KELM se esfuerza por achicar la distorsión y prosperar la precisión
- ¿Se empleará KELM pronto?
¿Qué es Kelm?
KELM es un acrónimo de Pre-Training del modelo de lenguaje mejorado por el saber, traducido precisamente como Pre-Training del modelo del lenguaje mejorado por el conocimiento.
En verdad, hay muchos modelos de procesamiento del lenguaje natural (PNL), una rama de la inteligencia artificial AI. En Inteligencia Artificial, el procesamiento del lenguaje natural es extremadamente difícil por el hecho de que implica adquirir y saber con precisión el significado del lenguaje. Desde ahí, contribuye a las computadoras a comprender y comunicarse con la gente mediante nuestro propio idioma.
BERT es un caso de muestra de un modelo de procesamiento de lenguaje natural apoyado en bases de datos web y documentos de artículo. Por otra parte, KELM puede sugerir que se agreguen hechos reales (expansión del conocimiento) al entrenamiento previo del modelo de lenguaje para progresar la precisión de los hechos y reducir el corte.

ALT: TEKGEN transforma los datos estructurados del gráfico de conocimiento en texto en lenguaje natural, llamado KELM Corpus
KELM utiliza datos enormemente confiables
Los estudiosos de Google+ recomiendan emplear
Los estudiosos de Google+ recomiendan utilizar Google+ Knowledge Graphs para prosperar la precisión de los hechos porque son fuentes confiables de datos.
"La fuente alternativa de información es el Gráfico de conocimiento (KG, abreviatura de Gráfico de conocimiento), que consta de datos estructurados. La naturaleza de KG es práctica, puesto que la información por norma general se extrae de fuentes mucho más confiables y filtros de posprocesamiento y el editor afirma que es inapropiado y también inexacto. Se eliminará el contenido ".
¿Google plus utiliza KELM?
Según fuentes actuales, no está claro si Google plus usó KELM. Sin embargo, esta es una forma prometedora de pre-entrenamiento de modelos de lenguaje que recientemente ha llamado la atención de Google plus.
Distorsión, precisión real y resultados de la búsqueda
La importancia de mejorar la precisión real citada en el informe de investigación es la siguiente:
"Esto tiene provecho de gran alcance en términos de prosperar la precisión real y achicar la malicia en el modelo de lenguaje generado".
Esta investigación es importante pues achicar el corte y progresar la precisión puede afectar la clasificación de los websites. Sin embargo, KELM aún no se ha utilizado y su encontronazo en los resultados de búsqueda de Google+ es ambiguo.
Evidentemente, Google plus no respalda ni verifica la precisión de los resultados de búsqueda ahora mismo.
Si se incluye KELM, uno puede imaginar que esto va a tener un impacto en los websites que fomentan declaraciones y también ideas imprecisas de la verdad.
KELM puede llevar a cabo más que influir en los resultados de la búsqueda
El corpus de KELM se publicó bajo la Licencia Creative Commons (CC BY-SA 2.0).
Eso quiere decir que, en teoría, cualquier otra compañía (como Bing, Facebook o Twitter) puede usarlo para progresar su capacitación anterior en el procesamiento del lenguaje natural.
Entonces, la predominación de KELM puede extenderse a múltiples interfaces de búsqueda y comunidades.
KELM asimismo está de forma indirecta con MUM. relacionados
Google+ asimismo decidió hasta tener la seguridad de que el prejuicio no afectaba negativamente los desenlaces. Entonces Google plus no publicará el algoritmo MUM de próxima generación.
Como lo anunció Google+ MUM:
“Hemos probado con bastante precaución muchas apps BERT que se publicaron desde 2019, y MUM va a pasar por exactamente el mismo desarrollo que utilizamos estos modelos en la búsqueda.
En particular, vamos a buscar patrones que indiquen sesgos en la educación automático para evitar ingresar cortes en nuestro sistema. "
El procedimiento KELM tiene como propósito concreto achicar la distorsión, lo que es muy útil para desarrollar algoritmos MUM.
El aprendizaje automático puede producir desenlaces ilusorios
Como afirma el documento, los datos de entrenamiento para modelos de lenguaje natural como BERT y GPT-3 "Contenido nocivo“Existe alguna variación.
Hay una palabra GIGO en el cálculo, que representa la oración Garbage In-Garbage Out. O sea, la calidad de la entrada determina que la calidad de la entrada sea altísima. Entonces, si adiestra el algoritmo con el mejor estándar de calidad, el resultado será de la correspondiente alta calidad.
Los estudiosos recomiendan mejorar la calidad de los datos capacitados usando tecnologías como BERT y MUM para eliminar el sesgo.
Gráfico de conocimiento Gráfico de conocimiento
Un gráfico de conocimiento es una colección de hechos en un formato de datos estructurados. Los datos estructurados son un lenguaje de marcado que se utiliza para trasmitir cierta información de una forma que sea simple de emplear para las máquinas.
En un caso así, la información son hechos sobre personas, sitios y cosas.
La introducción de Google plus Knowledge Graph está desarrollada para contribuir a Google plus a comprender la relación entre las cosas. Entonces, cuando alguien pregunta sobre Washington, Google+ puede entender si la persona que hace el interrogante está preguntando a la persona en Washington, el estado o el Distrito de Columbia.
En el aviso de Google+ de 2012, el Gráfico de conocimiento se describió como el primer paso en la construcción de la próxima generación de búsqueda que amamos hoy.
Mapa capaz y precisión práctica
En este trabajo de investigación, los datos del Gráfico de conocimiento se usan para mejorar el algoritmo de Google plus, puesto que esta información es confiable y fiable.
El trabajo de investigación de Google plus recomienda incorporar información de gráficos de conocimiento en el proceso de capacitación para remover los prejuicios y progresar la precisión de los hechos.
La investigación de Google+ muestra que es doble.
- Primero, necesitan traducir la base de conocimientos a texto en lenguaje natural.
- Seguidamente, el almacén de datos generado se conoce como preentrenamiento del modelo de lenguaje de mejora del conocimiento (KELM), que luego se puede integrar en el preentrenamiento del algoritmo para achicar el sesgo.
Los investigadores explicaron el inconveniente de esta manera:
"Los enormes modelos NLP (procesamiento de lenguaje natural) antes entrenados como BERT, RoBERTa, GPT-3, T5 y REALM utilizan corpus de lenguaje natural de fuentes web para refinar los datos concretos de la labor ...
Sin embargo, la proporción de conocimiento representada por el texto en lenguaje natural en sí tiene límites ... Además, la existencia de información poco realista y contenido malicioso en el texto ocasionalmente conduce a resultados sesgados en el modelo. "
Desde datos estructurados en gráficos de conocimiento hasta texto en lenguaje natural
Los estudiosos indicaron que un problema con la integración de la información de la base de conocimientos en el proceso de capacitación es que los datos de la base de entendimientos están en forma de datos estructurados.
La solución es utilizar una tarea de lenguaje natural llamada generación de datos a artículo para convertir datos de gráficos de conocimiento estructurados en artículo de lenguaje natural.
Aseguraron que convertir datos en texto los desafía a hacer lo que "tubería"Llamada"Artículo del generador de KG (TEKGEN)"Para resolver el inconveniente.
El artículo en lenguaje natural de TEKGEN optimización la precisión de los hechos
TEKGEN es una tecnología creada por estudiosos para transformar datos estructurados en artículo en lenguaje natural. Este es el resultado final, el texto real que se puede usar para hacer un corpus KELM que entonces se puede usar como parte del entrenamiento previo de aprendizaje automático para eludir sesgos intrusivos. Ingrese el algoritmo.
Los estudiosos señalaron que agregar estos gráficos de conocimiento adicionales (repositorio) a los datos de entrenamiento puede progresar la precisión real.
El producto de KELM publicó una ilustración que muestra cómo se conectan los nodos de datos estructurados y, desde ahí, se convierten en texto natural (oral).
tengo la ilustración dividida en 2 partes.
La siguiente es una representación de los datos estructurados del gráfico de conocimiento. Los datos están socios con el texto.
Atrapa de pantalla de la primera parte del proceso de conversión de TEKGEN

La siguiente ilustración exhibe el siguiente paso en el desarrollo de TEKGEN, que convierte artículo concatenado en texto en lenguaje natural.
Atrapa de pantalla de texto transformado a artículo en lenguaje natural

Crea un cuerpo KELM
Hay otra ilustración que exhibe de qué manera se usa el artículo en lenguaje natural de KELM para la formación previa.
El artículo de TEKGEN exhibe esta ilustración adjuntado con normas:
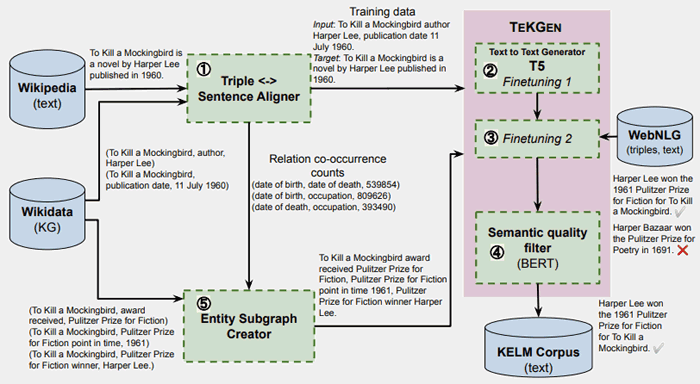
“En el paso 1, el trío de KG usó el monitoreo remoto para amoldarse al artículo de Wikipedia.
En los pasos 2 y 3, primero refine T5 en este corpus y luego realice algunos pequeños pasos en el corpus WebNLG.
En el paso 4, BERT se refina mucho más de tres ocasiones en el valor de calidad semántica de la oración generada.
`Los pasos 2, 3 y 4 entre ellos conforman TEKGEN.
Para hacer el corpus KELM en el paso 5, use los números de alineación de los pares de relaciones del corpus de entrenamiento creado en el paso 1 para hacer subgrafos de entidad.
Entonces use TEKGEN para transformar las tres subpáginas en artículo natural. "
KELM se esfuerza por achicar la distorsión y prosperar la precisión
El artículo de KELM publicado en el Blog de Inteligencia Artificial de Google plus indicó que KELM tiene apps reales. En especial para tareas de cuestiones y respuestas que están claramente similares con la restauración de información (búsqueda) y el procesamiento del lenguaje natural (tecnologías como BERT y MUM).
Google+ ha investigado mucho y algunos de ellos semejan estar explorando lo que es viable, pero en cuanto al resto semeja un callejón sin salida. La investigación que puede no estar incluida en el algoritmo de Google+ generalmente termina con la afirmación de que se necesita mucho más investigación pues la tecnología no ha cumplido relativamente las expectativas.
No obstante, este no es la situacion de los estudios de KELM y TEKGEN. De hecho, el archivo se muestra ilusionado sobre la app práctica de estos desenlaces. Esto aumenta la probabilidad de que KELM se una a la búsqueda de una manera u otra en algún momento.
Entonces los investigadores tienen KELM. productos resumidos para reducir el corte:
“Esto tiene usos reales para tareas intensivas en conocimiento, como responder cuestiones. Es imperativo impartir entendimientos prácticos en estas asignaciones. Además de esto, dicho corpus se puede aplicar al entrenamiento previo de modelos de lenguaje grandes y probablemente puede achicar las toxinas y acrecentar la autenticidad ".
¿Se empleará KELM pronto?
El algoritmo MUM comunicado recientemente por Google plus necesita precisión, para lo que se creó el almacén de datos KELM. Pero la app de KELM no se limita a MUM.
En verdad, achicar la distorsión y la precisión real es un tema importante en la sociedad de hoy, y el optimismo de los investigadores sobre los desenlaces con frecuencia les da una mayor posibilidad de ser usados en varios campos. Busque números de tabla futuros.
Fuente: www.searchenginejournal.com/google+-kelm/408151/
Deja una respuesta