
Optimice la velocidad del cibersitio con la captación previa de estudio automático

El tiempo de carga de la página (tiempo de carga de la página) pertence a los factores esenciales que determinan la experiencia del usuario en el sitio web. Hay muchos estudios que muestran que mejorar la velocidad del página web incrementa la tasa de conversión, aumenta la carga de la página y incrementa la satisfacción del cliente. El hipermercado Newegg tiene pruebas visibles. Al implementar la captación anterior para mejorar la velocidad de carga de la página, el total de conversiones se disminuye a la mitad.
En esta publicación de blog, probamos un fluído de trabajo de extremo a radical usando datos de navegación del sitio web de Google+ Analytics y entrenamos un modelo de aprendizaje automático personalizado para predecir sus próximas acciones. Puede utilizar estas predicciones en apps de Angular para obtener antes las páginas candidatas y progresar en buena medida la experiencia del usuario de su sitio web.
- Diagrama de alto nivel de la solución TensorFlow
- Preparación y adquisición de datos: elaborar y catalogar datos
- Entrenamiento de modelos: un paso importante en la utilización de Tensorflow Extended para mejorar la agilidad del sitio web
- Cree modelos que se puedan implementar en internet
- App de ángulo para optimizar la agilidad del página web
Diagrama de alto nivel de la solución TensorFlow
Utilice los servicios de Google plus Cloud (BigQuery y Dataflow) para recopilar y preprocesar datos de Google+ Analytics para su cibersitio. Estos datos se denominan datos de entrenamiento y se utilizan para entrenar modelos de algoritmos de estudio automático. Entonces, use TensorFlow Extended (TFX) para ajustar nuestro entrenamiento de modelos. Desde ahí, cree un modelo específico de portal web y conviértalo a un formato TensorFlow.js que se logre implementar en la web. Este modelo de cliente se carga en la aplicación web Angular de muestra de la tienda electrónica para demostrar de qué manera se incorpora el modelo en la aplicación web. Entendamos estos componentes con mucho más detalle.
Preparación y adquisición de datos: elaborar y catalogar datos
Además de proporcionar otros elementos como el nombre de la página, el tiempo de acceso y el tiempo de carga de la página, Google+ Analytics también registra cada vista de página como un acontecimiento. Los datos aquí son todo cuanto necesitamos para crear un prototipo, como por ejemplo:
1. Transforme los datos en ejemplos de entrenamiento con funciones y etiquetas.
2. Distribución a TFX para formación
Exporte los datos necesarios de Google+ Analytics para almacenarlos en un gran almacén de datos en la nube llamado BigQuery. Al crear una canalización de Apache Beam, podemos realizar el próximo desarrollo:
1. Leer datos de BigQuery
2. Ordenar y filtrar eventos en la sesión
3. Revise cada sesión y cree una plantilla con los atributos del evento de hoy como una característica y las vistas de página del próximo evento como una etiqueta.
4. Guarde estas muestras generadas en Google plus Cloud Storage para que TFX logre utilizarlas para la formación.
TFX opera la canalización de haces en Dataflow.
La siguiente es una tabla de ejemplo, cada columna se ajusta a un ejemplo de entrenamiento.

El ejemplo anterior tiene dentro solo 2 funciones de entrenamiento (cur_page y session_index). Además de esto, puede agregar de manera fácil otras funcionalidades de Google+ Analytics para hacer conjuntos de datos más enormes. A partir de ahí, los datos de salida se entrenan para hacer un modelo mucho más potente. Para realizar esto, expanda el siguiente código:

Entrenamiento de modelos: un paso importante en la utilización de Tensorflow Extended para mejorar la agilidad del sitio web
Tensorflow Extended (TFX) es una plataforma de estudio automático de un radical a otro en T-Scale que se emplea para automatizar la revisión de datos, entrenamiento riguroso (empleando aceleradores), evaluación y revisión para conseguir el modelo generado.
Para crear un modelo en TFX, precisa proporcionar un preprocesador y una función de ejecución. La función de preprocesador define las operaciones que se tienen que efectuar en los datos antes que se pasen al modelo principal. Estas incluyen operaciones que implican todas las transacciones de datos, como la generación de vocabulario. La función de ejecución define el modelo principal y su método de entrenamiento.
Nuestro ejemplo muestra de qué forma se implementan preprocessing_fn y run_fn para determinar y entrenar el modelo predictivo para la página siguiente. La canalización del ejemplo de TFX ilustra de qué forma se implementan estas funcionalidades para muchos otros casos de empleo.
Cree modelos que se puedan implementar en internet
Implemente y enlace el modelo a la red para realizar predicciones instantáneas sobre los usuarios que van a visitar el sitio. Luego, debe utilizar TensorFlow.js, que TensorFlow usa para ejecutar modelos de aprendizaje automático directamente en el navegador del cliente.
Al ejecutar este código en el lado del cliente, puede reducir el retardo asociado con el tráfico de ida y vuelta del lado del servidor, reducir los costes del lado del servidor y sostener la privacidad de los datos del usuario sin enviar los datos de la sesión al servidor.
TFX utiliza la biblioteca de reescritura de modelos para convertir de forma automática entre el modelo TensorFlow entrenado y el formato TensorFlow.js. Como parte de esta biblioteca, implementamos una reescritura de TensorFlow.js. Solo necesitamos llamar a este reescritor en run_fn para hacer la conversión precisa.
App de ángulo para optimizar la agilidad del página web
En el momento en que tenemos el modelo tenemos la posibilidad de emplearlo en nuestra app Angular para mejorar la agilidad del cibersitio. En cada navegación, consultamos el modelo y llamamos por adelantado qué recursos están vinculados a las páginas que se tienen la posibilidad de conocer en el futuro.
Otro método es usar todas y cada una de las posibles rutas de navegación futuras para conseguir recursos relacionados, pero esto consumirá mucho más ancho de banda. Con la educación automático, solo tenemos la posibilidad de adivinar qué páginas es mucho más probable que se usen ahora y reducir la cantidad de falsos positivos.
Dependiendo de la situación específica de la app, es posible que deseemos conseguir antes diferentes tipos de contenido. Por servirnos de un ejemplo JavaScript, imágenes o datos. Para esta demostración, vamos a buscar imágenes del producto.
¿Cómo lo implementa de manera eficaz?
Un desafío es llevar a cabo este mecanismo de forma efectiva sin perjudicar el tiempo de carga de la aplicación o el rendimiento del tiempo de ejecución. Las técnicas que podemos utilizar para achicar el riesgo de regresión del rendimiento son:
- Cargue el modelo y TensorFlow.js sin bloquear el tiempo de carga inicial de la página
- Consulta el modelo fuera del hilo primordial a fin de que no perdamos fotogramas en el hilo primordial y obtengamos una experiencia de renderizado a 60 fps
La API de la interfaz web que cumple con estas dos restricciones es el trabajador de servicios. El trabajador de servicio es un script, su navegador ejecuta un nuevo hilo en segundo plano, separado del sitio web. Asimismo le deja insertar ciclos de solicitud y le da control sobre el almacenamiento en caché.
Cuando los individuos navegan por la aplicación, enviaremos una notificación al personal de servicio para informarles de las páginas que han visitado. Según el historial de navegación, el personal de servicio predecirá la navegación futura y recuperará el contenido relevante del producto de antemano.
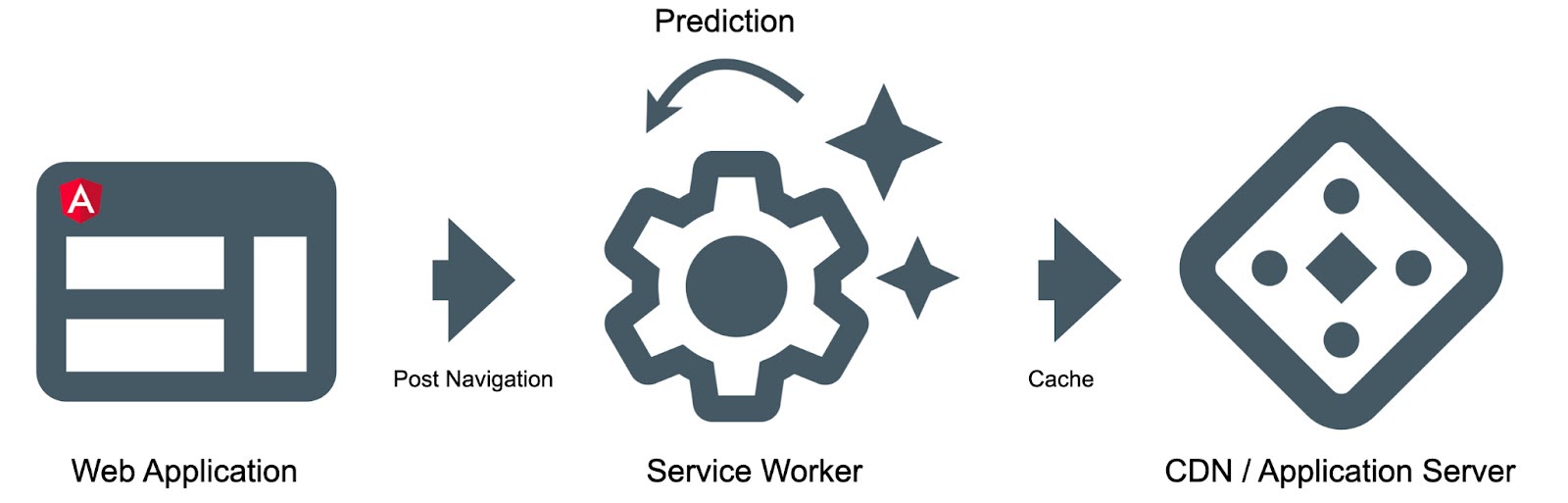
El trabajador del servicio se puede cargar desde el archivo angular primordial:

Este código descarga prefetch.worker.js y se ejecuta en background. Ahora, le mandamos los eventos de navegación:

En el código anterior, puede monitorear los cambios de los parámetros de URL. En el momento en que hacemos cambios, reenviamos el directorio del ubicación al personal de servicio.
En el desarrollo de implementación del trabajador del servicio, requerimos procesar los mensajes del hilo principal, hacer predicciones fundamentadas en los mensajes y conseguir previamente la información importante. En un nivel prominente se ve de esta forma fuera:

Debe estar atento a los mensajes del hilo primordial en el trabajador del servicio. Tras recibir el mensaje de inicio del disparador, realice predicciones y obtenga datos antes.
En la función de captación previa, predecimos qué páginas visitará el usuario a continuación. Entonces iteramos todas y cada una de las predicciones y obtenemos los elementos para mejorar la experiencia del usuario de la próxima navegación.
Nguồn: utilice la educación automático para acelerar su página web mediante la búsqueda previa de páginas
Deja una respuesta