
Bibliotecas Python útiles para SEO y cómo usarlas

Las bibliotecas de Python son una forma divertida y accesible de comenzar a aprender y usar Python para SEO.
Una biblioteca de Python es una colección de funciones y código útiles que le permiten completar una serie de tareas sin necesidad de escribir el código desde cero.
Hay más de 100,000 bibliotecas disponibles para usar en Python, que se pueden usar para funciones desde el análisis de datos hasta la creación de videojuegos.
En este artículo, encontrará varias bibliotecas diferentes que he usado para completar proyectos y tareas de SEO. Todos ellos son aptos para principiantes y encontrará una gran cantidad de documentación y recursos para ayudarlo a comenzar.
¿Por qué las bibliotecas de Python son útiles para SEO?
Cada biblioteca de Python contiene funciones y variables de todo tipo (matrices, diccionarios, objetos, etc.) que se pueden utilizar para realizar diferentes tareas.
Para SEO, por ejemplo, se pueden usar para automatizar ciertas cosas, predecir resultados y proporcionar información inteligente.
Es posible trabajar solo con Python vanilla, pero las bibliotecas se pueden usar para hacer que las tareas sean mucho más fáciles y rápidas de escribir y completar.
Bibliotecas de Python para tareas de SEO
Hay una serie de bibliotecas Python útiles para tareas de SEO que incluyen análisis de datos, raspado web y visualización de información.
Esta no es una lista exhaustiva, pero estas son las bibliotecas que más utilizo para fines de SEO.
Pandas
Pandas es una biblioteca de Python que se utiliza para trabajar con datos de tablas. Permite la manipulación de datos de alto nivel donde la estructura de datos clave es un DataFrame.
Los DataFrames son similares a las hojas de cálculo de Excel, sin embargo, no se limitan a los límites de filas y bytes y también son mucho más rápidos y eficientes.
La mejor manera de comenzar con Pandas es tomar un simple CSV de datos (un rastreo de su sitio web, por ejemplo) y guardarlo en Python como un DataFrame.
Una vez que tenga esto almacenado en Python, puede realizar una serie de tareas de análisis diferentes, incluida la agregación, la rotación y la limpieza de datos.
Por ejemplo, si tengo un rastreo completo de mi sitio web y quiero extraer solo aquellas páginas que son indexables, usaré una función Pandas incorporada para incluir solo esas URL en mi DataFrame.
import pandas as pd
df = pd.read_csv('/Users/rutheverett/Documents/Folder/file_name.csv')
df.head
indexable = df[(df.indexable == True)]
indexable
Peticiones
La siguiente biblioteca se llama Solicitudes y se usa para realizar solicitudes HTTP en Python.
Las solicitudes utilizan diferentes métodos de solicitud, como GET y POST, para realizar una solicitud, y los resultados se almacenan en Python.
Un ejemplo de esto en acción es una simple solicitud GET de URL, esto imprimirá el código de estado de una página:
import requests
response = requests.get('https://www.deepcrawl.com') print(response)
Luego, puede usar este resultado para crear una función de toma de decisiones, donde un código de estado 200 significa que la página está disponible, pero un 404 significa que no se encuentra la página.
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
También puede usar diferentes solicitudes, como encabezados, que muestran información útil sobre la página, como el tipo de contenido o cuánto tiempo se tardó en almacenar en caché la respuesta.
headers = response.headers print(headers) response.headers['Content-Type']
También existe la capacidad de simular un agente de usuario específico, como Googlebot, para extraer la respuesta que verá este bot específico al rastrear la página.
headers = 'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' ua_response = requests.get('https://www.deepcrawl.com/', headers=headers) print(ua_response)
Sopa hermosa
Beautiful Soup es una biblioteca que se utiliza para extraer datos de archivos HTML y XML.
Dato curioso: la biblioteca BeautifulSoup en realidad recibió su nombre del poema de Alicia en el país de las maravillas de Lewis Carroll.
Como biblioteca, BeautifulSoup se usa para dar sentido a los archivos web y se usa con mayor frecuencia para el raspado web, ya que puede transformar un documento HTML en diferentes objetos de Python.
Por ejemplo, puede tomar una URL y usar Beautiful Soup junto con la biblioteca de solicitudes para extraer el título de la página.
from bs4 import BeautifulSoup import requests url="https://www.deepcrawl.com" req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") title = soup.title print(title)

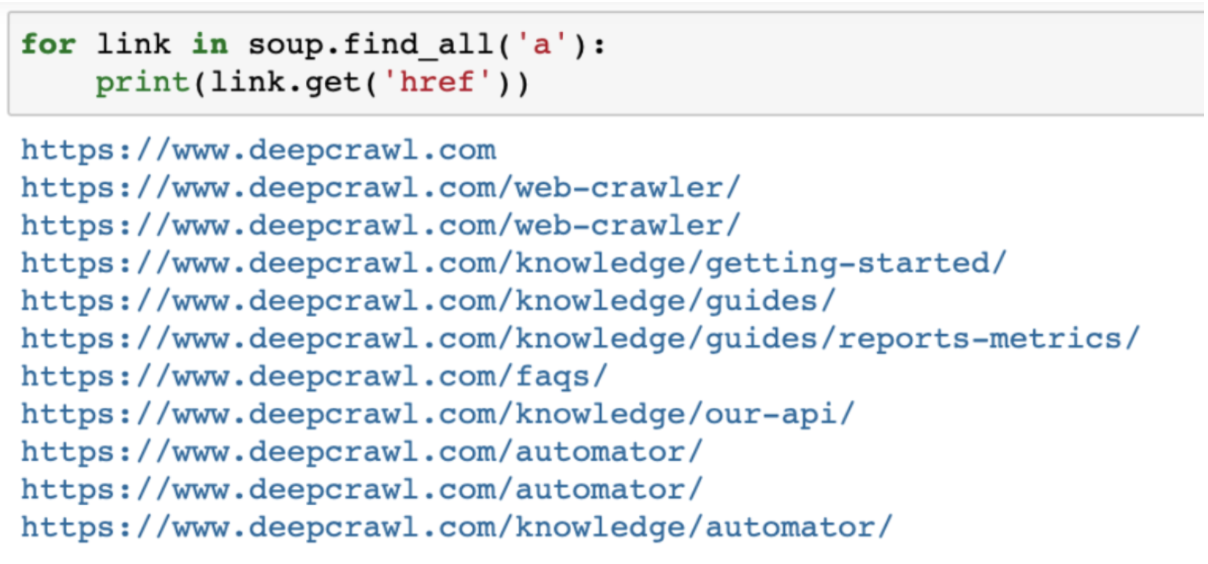
Además, utilizando el método find_all, BeautifulSoup le permite extraer ciertos elementos de una página, como todos los enlaces href de la página:
url="https://www.deepcrawl.com/knowledge/technical-seo-library/"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
Poniéndolos juntos
Estas tres bibliotecas también se pueden usar juntas, y las solicitudes se usan para realizar la solicitud HTTP a la página de la que nos gustaría usar BeautifulSoup para extraer información.
Luego, podemos transformar esos datos sin procesar en un Pandas DataFrame para realizar un análisis adicional.
URL = 'https://www.deepcrawl.com/blog/'
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
links = soup.find_all('a')
df = pd.DataFrame('links':links)
df
Matplotlib y Seaborn
Matplotlib y Seaborn son dos bibliotecas de Python que se utilizan para crear visualizaciones.
Matplotlib le permite crear una serie de visualizaciones de datos diferentes, como gráficos de barras, gráficos de líneas, histogramas e incluso mapas de calor.
Por ejemplo, si quisiera tomar algunos datos de Tendencias de Google para mostrar las consultas con mayor popularidad durante un período de 30 días, podría crear un gráfico de barras en Matplotlib para visualizar todas estas.

Seaborn, que se basa en Matplotlib, proporciona aún más patrones de visualización, como diagramas de dispersión, diagramas de caja y diagramas de violín, además de gráficos de líneas y barras.
Se diferencia ligeramente de Matplotlib ya que usa menos sintaxis y tiene temas predeterminados incorporados.
Una forma en la que he usado Seaborn es crear gráficos de líneas para visualizar los accesos de archivos de registro a ciertos segmentos de un sitio web a lo largo del tiempo.

sns.lineplot(x = "month", y = "log_requests_total", hue="category", data=pivot_status) plt.show()
Este ejemplo en particular toma datos de una tabla dinámica, que pude crear en Python usando la biblioteca Pandas, y es otra forma en que estas bibliotecas trabajan juntas para crear una imagen fácil de entender a partir de los datos.
Advertools
Advertools es una biblioteca creada por Elias Dabbas que se puede utilizar para ayudar a administrar, comprender y tomar decisiones basadas en los datos que tenemos como profesionales de SEO y comercializadores digitales.
Análisis del mapa del sitio
Esta biblioteca le permite realizar una serie de tareas diferentes, como descargar, analizar y analizar sitemaps XML para extraer patrones o analizar la frecuencia con la que se agrega o cambia el contenido.
Análisis de Robots.txt
Otra cosa interesante que puede hacer con esta biblioteca es utilizar una función para extraer el archivo robots.txt de un sitio web en un DataFrame, con el fin de comprender y analizar fácilmente el conjunto de reglas.
También puede ejecutar una prueba dentro de la biblioteca para verificar si un agente de usuario en particular puede obtener ciertas URL o rutas de carpeta.
Análisis de URL
Advertools también le permite analizar y analizar URL para extraer información y comprender mejor los análisis, las SERP y los datos de rastreo para ciertos conjuntos de URL.
También puede dividir las URL utilizando la biblioteca para determinar cosas como el esquema HTTP que se está utilizando, la ruta principal, los parámetros adicionales y las cadenas de consulta.
Selenio
El selenio es una biblioteca de Python que generalmente se usa con fines de automatización. El caso de uso más común es probar aplicaciones web.
Un ejemplo popular de la automatización de un flujo de Selenium es un script que abre un navegador y realiza una serie de pasos diferentes en una secuencia definida, como completar formularios o hacer clic en ciertos botones.
Selenium emplea el mismo principio que se usa en la biblioteca de solicitudes que cubrimos anteriormente.
Sin embargo, no solo enviará la solicitud y esperará la respuesta, sino que también mostrará la página web que se solicita.
Para comenzar con Selenium, necesitará un WebDriver para poder interactuar con el navegador.
Cada navegador tiene su propio WebDriver; Chrome tiene ChromeDriver y Firefox tiene GeckoDriver, por ejemplo.
Estos son fáciles de descargar y configurar con su código Python. Aquí hay un artículo útil que explica el proceso de configuración, con un proyecto de ejemplo.
Scrapy
La biblioteca final que quería cubrir en este artículo es Scrapy.
Si bien podemos usar el módulo de Solicitudes para rastrear y extraer datos internos de una página web, para pasar esos datos y extraer información útil, también debemos combinarlo con BeautifulSoup.
Scrapy esencialmente le permite hacer ambas cosas en una biblioteca.
Scrapy también es considerablemente más rápido y más poderoso, completa solicitudes para rastrear, extrae y analiza datos en una secuencia establecida y le permite proteger los datos.
Dentro de Scrapy, puede definir una serie de instrucciones, como el nombre del dominio que le gustaría rastrear, la URL de inicio y ciertas carpetas de páginas que la araña puede o no rastrear.
Scrapy se puede utilizar para extraer todos los enlaces en una página determinada y almacenarlos en un archivo de salida, por ejemplo.
class SuperSpider(CrawlSpider):
name="extractor"
allowed_domains = ['www.deepcrawl.com']
start_urls = ['https://www.deepcrawl.com/knowledge/technical-seo-library/']
base_url="https://www.deepcrawl.com"
def parse(self, response):
for link in response.xpath('//div/p/a'):
yield
"link": self.base_url + link.xpath('.//@href').get()
Puede dar un paso más y seguir los enlaces que se encuentran en una página web para extraer información de todas las páginas a las que se enlaza desde la URL de inicio, como una réplica a pequeña escala de los enlaces de búsqueda y seguimiento de Google en una página.
from scrapy.spiders import CrawlSpider, Rule
class SuperSpider(CrawlSpider):
name="follower"
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Web_scraping']
base_url="https://en.wikipedia.org"
custom_settings =
'DEPTH_LIMIT': 1
def parse(self, response):
for next_page in response.xpath('.//div/p/a'):
yield response.follow(next_page, self.parse)
for quote in response.xpath('.//h1/text()'):
yield 'quote': quote.extract()
Deja una respuesta